 If you are a Python programmer, you might be interested to know that you can get a free PDF of Python in a Nutshell, 2nd Edition from IT ebBooks. It's a few year's old now but still has a lot of useful basic Python syntax. It doesn't cover Python 3, so if you are a newbie you might want to hunt down some specific advice about programming Python 3 compatible code in Python 2.7. (To be honest, I still haven't plucked up the courage to look at the Python 2 vs. Python 3 difference myself but it might be worth having a go at the Python 3 tutorial.)
If you are a Python programmer, you might be interested to know that you can get a free PDF of Python in a Nutshell, 2nd Edition from IT ebBooks. It's a few year's old now but still has a lot of useful basic Python syntax. It doesn't cover Python 3, so if you are a newbie you might want to hunt down some specific advice about programming Python 3 compatible code in Python 2.7. (To be honest, I still haven't plucked up the courage to look at the Python 2 vs. Python 3 difference myself but it might be worth having a go at the Python 3 tutorial.)
Showing posts with label programming. Show all posts
Showing posts with label programming. Show all posts
Monday, 10 June 2013
Python in a Nutshell - free PDF available!
If you are a Python programmer, you might be interested to know that you can get a free PDF of Python in a Nutshell, 2nd Edition from IT ebBooks. It's a few year's old now but still has a lot of useful basic Python syntax. It doesn't cover Python 3, so if you are a newbie you might want to hunt down some specific advice about programming Python 3 compatible code in Python 2.7. (To be honest, I still haven't plucked up the courage to look at the Python 2 vs. Python 3 difference myself but it might be worth having a go at the Python 3 tutorial.)
Saturday, 8 June 2013
Marvellous Markdown
Another positive outcome of the recent Software Carpentry boot camp was the excuse and opportunity to get a bit more to grips with Markdown. This is really useful pseudocode that retains a high degree of human readability in plain text form, whilst being easily converted to HTML and other rich text formats. I'd already used it a bit for some of my content on the University of Southampton Computational Modelling Group website but I'd never fully realised its flexibility, value and potential until I started writing README files in it.
I won't try to explain Markdown itself here. The Wikipedia article is pretty informative if you want to know more. Instead, this a quick post to highlight/bookmark some useful Markdown tools that I've come across.
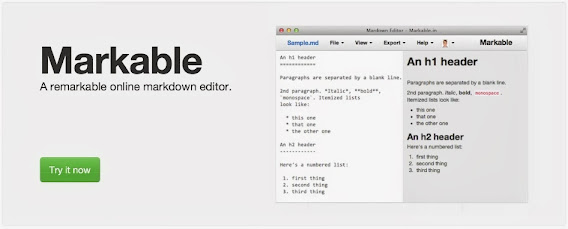
This is great if you just want to try your hand at a bit of Markdown and see what the HTML conversion would look like. Simply type your text in the online Markable editor and the HTML window will automatically update to reflect the changes! You can then copy the Markdown to the clipboard or export Markdown/HTML to a file.

If you see yourself using Markdown a lot, as I now do, you can register and take advantage of a whole bunch of other tools, such as (auto)saving content to work on later or exporting the Markdown (or HTML) directly into Dropbox.
I won't try to explain Markdown itself here. The Wikipedia article is pretty informative if you want to know more. Instead, this a quick post to highlight/bookmark some useful Markdown tools that I've come across.
Markable
The first is the Markable website.
This is great if you just want to try your hand at a bit of Markdown and see what the HTML conversion would look like. Simply type your text in the online Markable editor and the HTML window will automatically update to reflect the changes! You can then copy the Markdown to the clipboard or export Markdown/HTML to a file.

If you see yourself using Markdown a lot, as I now do, you can register and take advantage of a whole bunch of other tools, such as (auto)saving content to work on later or exporting the Markdown (or HTML) directly into Dropbox.

Markdown Service Tools
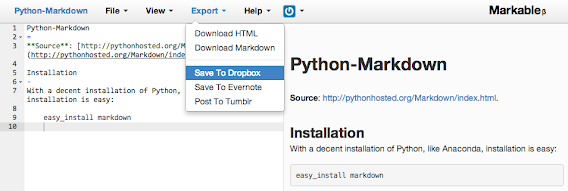
Of course, if you are like me then saving to HTML code might not be enough for you. You might want to see the HTML code and/or copy it for use elsewhere. (I write all my blog posts in the HTML editor, for example.) On a Mac there is the tremendously useful Markdown Service Tools by Brett Terpstra that, among other things, includes tools for precisely this. Simply download the zip file, unpack and then copy the relevant *.workflow files to your OS X System Service folder:~/Library/Services/Python-Markdown
It's worth quickly mentioning that there's a Markdown Python library, if for no other reason than that is appears in the Markable screen grab above! This can be used for easy conversions between formats, which might be handy for coding up batch conversions of *.md to HTML README files etc. I really need to save this one for another day as I am still getting to grips with it and working out how/where it can be useful for me.Wednesday, 5 June 2013
Six useful things I have learnt at Software Carpentry boot camp
 Monday and Tuesday this week, I attended a Software Carpentry boot camp at the University of Southampton. Topics covered included bash, shell scripting, Git and writing/testing reproducible code. The event was well-attended and whilst making an event like this relevant to everyone is obviously a challenge, they did a great job. I certainly learnt some useful tips even for the topics that I knew a fair bit about.
Monday and Tuesday this week, I attended a Software Carpentry boot camp at the University of Southampton. Topics covered included bash, shell scripting, Git and writing/testing reproducible code. The event was well-attended and whilst making an event like this relevant to everyone is obviously a challenge, they did a great job. I certainly learnt some useful tips even for the topics that I knew a fair bit about.As well as the SWC presentations themselves, it was good to get tips from fellow programmers as well as "UNIX and Perl to the Rescue!: A Field Guide for the Life Sciences (and Other Data-rich Pursuits)", which I brought along for some browsing. Here is half a dozen random things that I picked up over the two days...
1. Useful grep flags. I've used
grep to pull out matches from text files a fair amount and was familiar with a few of the flags that I use a lot:I learnt a few more useful ones, though:-i= case-insensitive search
-v= inverse search
-A n= return n lines after match
-B n= return n lines before match
2. Useful ls flags.-w= match whole words only
-n= show line numbers
--color= highlight matches in colour
-r= search subdirectories (recursive)
ls is another must-have part of the UNIX users toolkit. There were still a few useful flags with which I was unfamiliar and am likely to use in future, though:Along with my old favourites, of course:-G= colour-code directory contents
-F= appends / to directories
-R= recursive ls including subdirectory contents
-1= one entry per line
-a= show all files including hidden files
3. Catching the standard error and standard output. I've seen this a few times but for some reason this was the first time it really sunk in. Most UNIX users will be familiar with redirecting the standard output from a command into a file using-l= "long" mode (more info)
-r= reverse sort
-t= sort by time
-S= sort by size
-h= user-friendly file sizes
> file (or >> to append). Catching the standard error is less obvious/common. This can be done using 2> to catch the stderr alone, or &> to catch both stdout and stderr at the same time. If you want to redirect them both into different files, do something like this:[cmd] 2> error.txt > stdout.txt4. Navigating the terminal. This one actually came from "UNIX and Perl to the Rescue" but I discovered it at the boot camp:
UsingCtrl+a= move to start of line
Ctrl+e= move to end of line
Ctrl+w= delete previous word
Ctrl+l= clear screen (clearworks too)
Ctrl+r= search through previous commands one letter at a time (this was an SWC revelation)
Ctrl+a and Ctrl+e seems to work in a number of other Mac editors too - including this blogger HTML window! If you are a Mac user, just make sure that you don't use cmd+w by mistake - this will close the current terminal window with much wailing and gnashing of teeth!5. Reversing Python strings. In the past, I have reversed a python string by converting into a list, using the
list.reverse() method and then string.join() to convert it back. But there is a better way!string[::-1]range() method! (string[::-1] translates as string[start=end:end=start:step=-1].) Now I am wondering where else in my code I can use this knowledge!6. Changing the command prompt to $. Sometimes, the command prompt is too long (or the terminal window too narrow) so that almost every command wraps around in an annoying fashion. To replace with a simple $ character, just type:
PS1="\s"
PS1="\$ "
pwd gives you the full path to the working directory.There were more but I think that's enough for now! If this is the sort of thing that floats your boat, you can find useful stuff like this plus a whole bunch of lessons at the Software Carpentry website:
If you get the chance to attend a boot camp yourself, my advice is: do!
Sunday, 29 April 2012
SeqSuite: another blog is born
Although this is my blog, I feel a bit funny about explicitly blogging about work stuff in a blatant "look at what I've done, please read/use/cite it!" fashion. I have therefore created a new blog explicitly for that side of things. Actually, it has existed for a while but not really had much content until today's post about SLiMMaker (my second solo excursion into python CGI). The blog is currently titled SeqSuite: open-source bioinformatics in Python and the central theme is the application and development of the various tools that I have cobbled together over the years, although I hope to diversify into other related stuff should time allow.
The main focus is actually SLiMSuite, which is the collection of short linear motif (SLiM) tools that I have been involved in developing. (The term "SLiM" will probably be my longest lasting contribution to science. It's weird seeing it start to appear in textbooks! (Although I must point out that I did not invent the concept. I'll save SLiMs for another post, I think.)) SLiMSuite is both the main pillar of my research but also, I think, the more original and unique of my software. (Some of the other stuff I have made because I have been too lazy to hunt down something that does what I want.)
Despite the ascendancy of SLiMSuite, I've stuck with "SeqSuite" as the name, though, as (a) other "Slim Suites" seem to exist and I want to head off any legal objections in advance, and (b) I have some other tools that are nothing to do with SLiMs and, along with SLiMSuite, form the larger SeqSuite package.
I'm still not entirely sure how the two blogs will work - finding the time to write one blog is hard enough - but I think I will continue to post the more "human" aspect of work-related matters here, and the more technical aspects on the SeqSuite blog. (Hopefully, I can convince some of my collaborators to contribute there too.) I think, like a lot of academics, I realise the importance of trying to communicate what we do, but haven't quite worked out yet the best way to go about it.
The main focus is actually SLiMSuite, which is the collection of short linear motif (SLiM) tools that I have been involved in developing. (The term "SLiM" will probably be my longest lasting contribution to science. It's weird seeing it start to appear in textbooks! (Although I must point out that I did not invent the concept. I'll save SLiMs for another post, I think.)) SLiMSuite is both the main pillar of my research but also, I think, the more original and unique of my software. (Some of the other stuff I have made because I have been too lazy to hunt down something that does what I want.)
Despite the ascendancy of SLiMSuite, I've stuck with "SeqSuite" as the name, though, as (a) other "Slim Suites" seem to exist and I want to head off any legal objections in advance, and (b) I have some other tools that are nothing to do with SLiMs and, along with SLiMSuite, form the larger SeqSuite package.
I'm still not entirely sure how the two blogs will work - finding the time to write one blog is hard enough - but I think I will continue to post the more "human" aspect of work-related matters here, and the more technical aspects on the SeqSuite blog. (Hopefully, I can convince some of my collaborators to contribute there too.) I think, like a lot of academics, I realise the importance of trying to communicate what we do, but haven't quite worked out yet the best way to go about it.
Tuesday, 24 April 2012
CGI, where've you bin all my life?
I'd been meaning to play around with CGI (Common Gateway Interface) programming for some time as a way of making simple functional websites. I finally got round to it last month, thanks to a great introductory page at Tutorials Point. What I did not realise is quite how easy it was.
I've still only really scratched the surface and scanned over the page to get something up quickly but, in essence, you only need three things:
My first attempt at this can be found here. It's a bit of silly fun but it shows what can be done with just a few simple lines of code. I've cheated a little bit by using an existing python module to generate the middle of the HTML code but, in a way, that's the point - you can easily adapt existing functional code to output text.
In this case, I use the random "Zen wisdom" text strings that are generated in my code to lighten up error messages when I'm debugging. (If you ever use one of my programs, you sometimes come across such an error message, which always causes confusion (and usually embarrassment for me!) but I think it's a small price to pay for making debugging more fun!) The scary thing is how often the random Zen Wisdoms sound deep and meaningful, e.g.
I've still only really scratched the surface and scanned over the page to get something up quickly but, in essence, you only need three things:
1. A webserver that supports CGI.And that's essentially it. Actually, you don't even need (2), as you can feed variables directly to the cgi script, but it makes it easier for the user, I think.
2. An html page containing some "form" code that contains a submit button and (optionally) some input options (e.g. text boxes or checkboxes).
3. A python script (or another language) that generates HTML code based on the variables and values from the form.
My first attempt at this can be found here. It's a bit of silly fun but it shows what can be done with just a few simple lines of code. I've cheated a little bit by using an existing python module to generate the middle of the HTML code but, in a way, that's the point - you can easily adapt existing functional code to output text.
In this case, I use the random "Zen wisdom" text strings that are generated in my code to lighten up error messages when I'm debugging. (If you ever use one of my programs, you sometimes come across such an error message, which always causes confusion (and usually embarrassment for me!) but I think it's a small price to pay for making debugging more fun!) The scary thing is how often the random Zen Wisdoms sound deep and meaningful, e.g.
"It is bold to play jenga with blocks of passion."Well, maybe not that deep and meaningful!
Friday, 16 March 2012
Python ValueError: bad marshal data
I have been programming for many years but consider myself to be somewhat of an "empirical programmer", i.e. I am almost entirely self-taught. As a result, I sometimes come across new and exciting error messages that I have neither encountered nor understand. I have just had one such error:
I still don't know what bad marshal data is (it sounds like it should be something to do with Wild West movies) but, fortunately, I have found an easy fix: just delete all the compiled *.pyc files. Missing ones are remade when you run your python code anyway. Problem solved without any need to delve into the murky underworld of bad marshals.
ValueError: bad marshal dataThis was associated with an import command for several modules.
I still don't know what bad marshal data is (it sounds like it should be something to do with Wild West movies) but, fortunately, I have found an easy fix: just delete all the compiled *.pyc files. Missing ones are remade when you run your python code anyway. Problem solved without any need to delve into the murky underworld of bad marshals.
Subscribe to:
Posts (Atom)